
wants to build large scale data processing systems.
Searching Git repositories seems to be a very trivial problem of retrieval of web data. Though it exhibits some very interesting similarities with the standard process of document retrieval, it is proves to be a different domain of search altogether. Code matching is altogether a different field of research, but the model for document matching in standard retrieval can surely be adopted and implemented to process search queries on Git repositories. Meanwhile, search on Github is primarily a boolean search with static ranking system based on ‘stars’ and ‘watch’ count of the retrieved repositories. It takes no measure for matching ‘content’ of the repository with the search query which limits its scope of retrieval to almost specific and shallow searches only.
# calculating relevance :
We propose a vector-space model for retrieval of relevant repositories based on the user query. Since there is no specific document to consider for the description of the repository, multiple sources of text in a repository are considered to form the “bag of words” viz. title of the repository, short description, README.md file, and any other text files in the document. The words from these sources are weighted in order : title > description > README.md > others and contribute to the collection of words from a repository. The weight of words are then multiplied with their corresponding tf-idf scores to give the vector corresponding to a repository.
Similar vector is formulated for the user query as well, and cosine-similarity with each repository is calculated to reveal the most significant repositories for a query. The vector-space model, as implemented, gives evident results for the posed queries, on the test set :
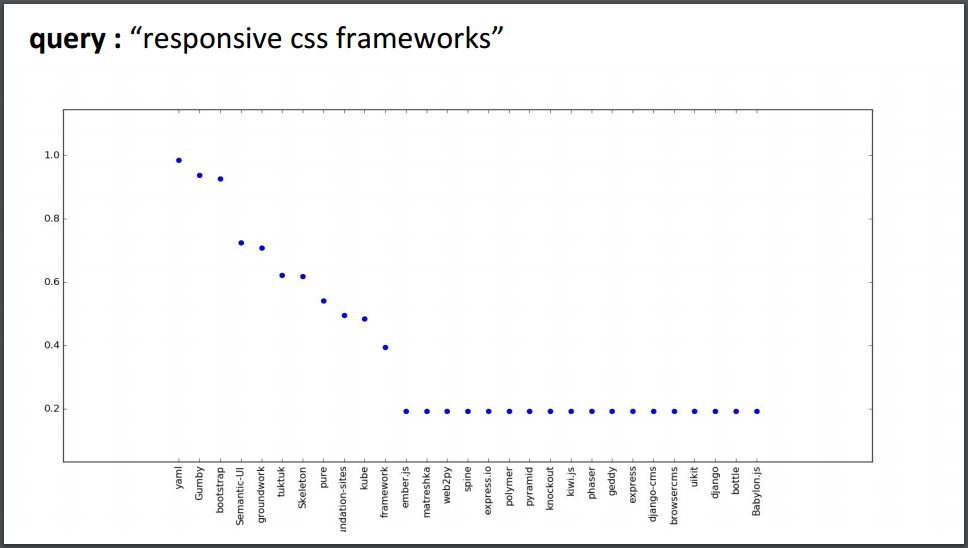
We use 2-mean hierarchical clustering on this result to separate non-relevant set of repositories { underlying set of points in the graph } from a more prominent relevant set.
# calculating health of a repository :
The textual relevance of the repository does not satisfy the actual need of someone who is searching on Github. A user looks for the code repo that is well-maintained, updated, have efficient bug redressal, great collaboration and user popularity. The above listed aspects can be said to contribute to the ‘health’ of the repository in Github. They serve as an indicator to the stability of a repo and probables of using it, apart from being relevant to the user. Hence, the repos high on such features must be ranked higher in the list of relevant repositories fetched by the retrieval system for a user query.
Hence, the updated workflow for processing user query now becomes :
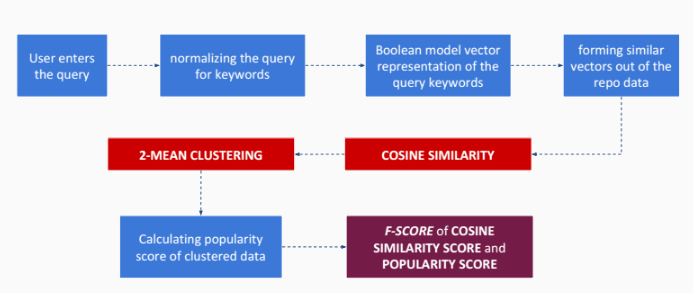
The factors we have considered for health of the repository are :
- number of stars, watches, and forks.
- pull requests : total, open, closed, merged
- issues : total, open, closed
- total contributors, active contributors
- version releases, stability of releases, frequency, timespan
- project wiki : yes/no
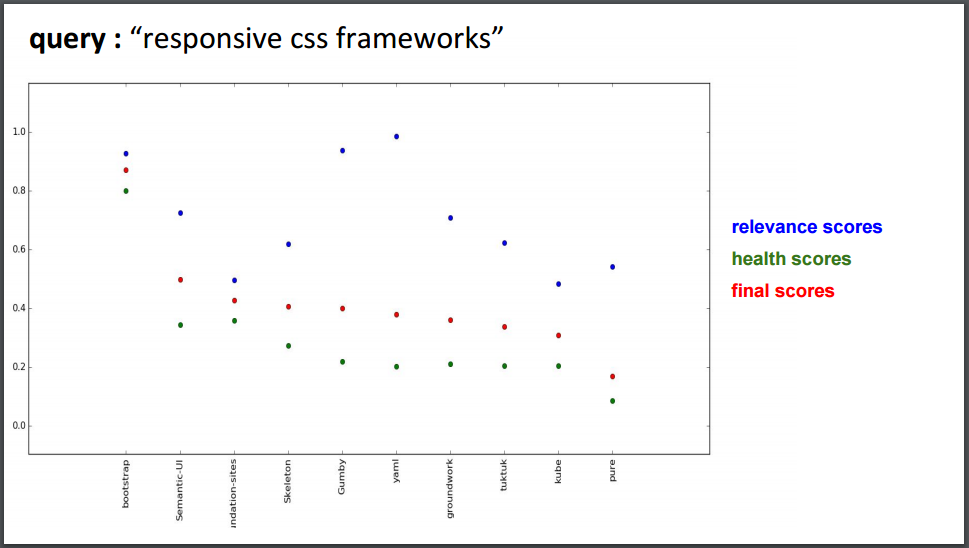
Each aspect is weighted between [0,1] using derived measures and is given a fixed percentage in contribution to the total health. The relative scores of the health analysis is taken out, which is merged with the scores of text relevance using F-beta scoring to get the final rankings.
The example with the final scores gives a much improved ranking of relevant repositories after considering the health :
Github
https://github.com/g31pranjal/git-analysis
# The team
A Anjana, Himanshu Singh Dhoni, Shubhi Rastogi and me.