
wants to build large scale data processing systems.
This was done as part of the Final Project for the cource CS 798: Advanced Topics in Computer Science: Distributed Sysetms.
# Evaluation of different workloads:
In the first part of the project we experimentally study the various performance metrics associated with running functions on a Serverless computing architecture. We used a setup consisting of Docker Containers for encapsulating workloads, Kubernetes network on a 6 node cluster for container orchestration and the Open-FaaS framework to listen to function execution requests. We designed 4 workloads that is representative of different scenarios of functions utilization. These were as follows:
- Ping: Simple function call that basically does nothing. The aim of running this workload is to measure network latency overhead (if any) in the serverless environment. We did two variants of experiments using this workload: hot-start (relevant containers were up and running on nodes), and cold-start (no dockers were running on any of the nodes).
- Computation Intensive: This workload does heavy computation like creating factorial of a very big number. The idea with this workload was to study computation overhead that incurred on nodes.
- I/O Intensive: Does a lot of I/O request to the underlying NFS. Idea is to measure the network latency and throughput for huge data transfers.
- Scalability: Finally we design a workload to study the automatic and manual scalability of the architecture. We essentially carry the experiment by generating varied number of requests to the Open-FaaS API and note down the response time and request drops.
# MapReduce
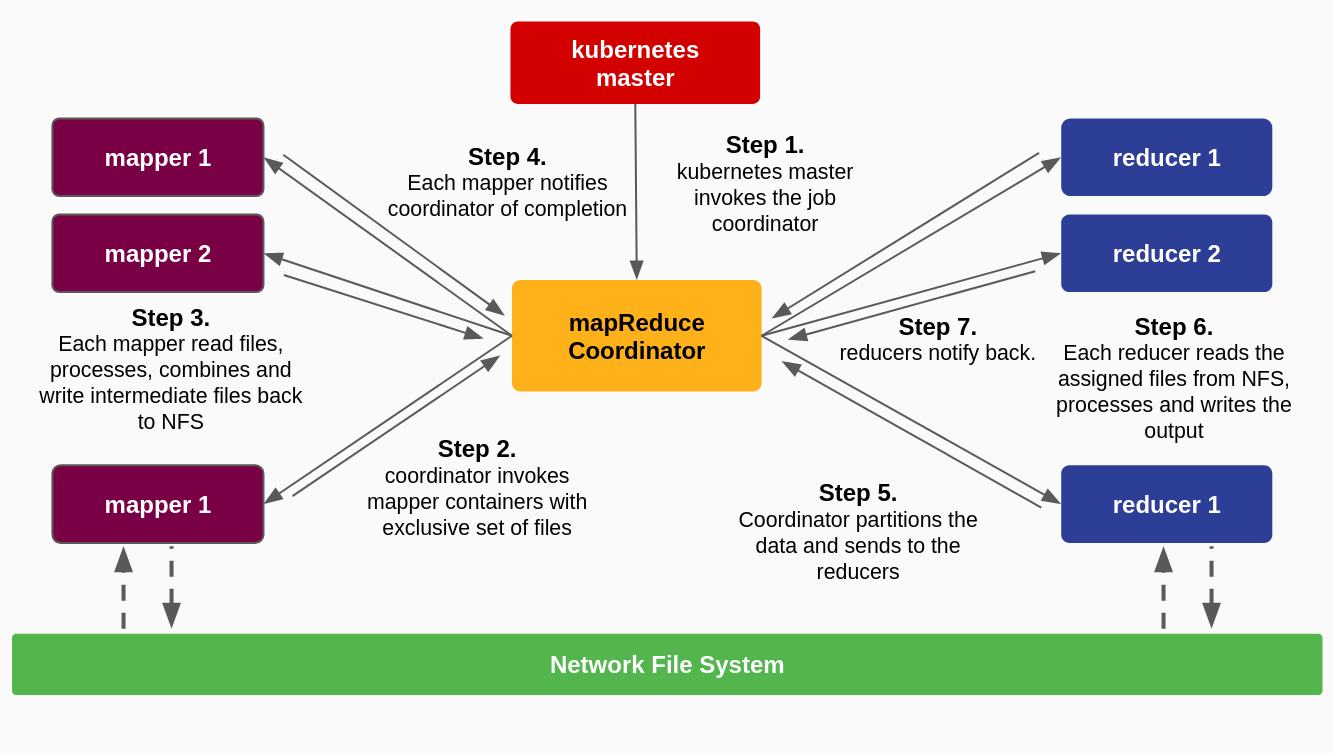
In this part of the project, we take a simple workload and solve it using the MapReduce paradigm on the serverless architecture. Our task was to count the frequency for each unique word that appeared in a multi-billion text corpus. We design a 1-stage reducer job which was loosely inspired by this Amazon AWS article. Out system design is as illustrated:
# Results
We report important metrics like the round trip time, I/O overhead and latency, computation overhead and finally an analysis on how the system scales with the change in number of nodes in the cluster and requests per second. Finally we draw important inferences with respect to the scaling policy and end-to-end system workflow.
The results are too large to be put here. See the project report.
# Team:
Shreesha Addala and me :)